I couldn't tell you how many times I've tried to use a Haskell library, only to pop open the Hackage documentation to see something like this:
Or this:
Hmm. Okay. I have no idea how to actually use these libraries from just this documentation. Where are the usage examples? What does this library actually do?
Now, granted, Hakyll is meant to be learned through its own website, not through browsing through Haddock documentation. But Haskell projects that have even this level of documentation seem to be few and far between, even for cornerstones of the community! (I'm looking at you, lens.) So if you're trying to use a Haskell library to solve your problem, oftentimes you might not be able to figure out how to use it because there are no examples or synopsis.
The real solution to this problem would be for the community to collectively write better and more end-user focused documentation. But since that's not likely to happen anytime soon, if you're planning on using Haskell, you'll have to learn how to glean information from even Hackage documentation as sparse as the examples above.
The first thing I try to do when I see some documentation like this is to try to figure out what its domain-specific types mean. This is one of the big strengths of reading Haskell: if you know what the types are, you don't necessarily need a lot of documentation to figure out what a function or some code does; you can just infer that from the type and the function name! But conversely, until you know what the types mean, the code will make no sense.
All this means that we should start figuring out a library by figuring out its types. Not too surprising, given how much emphasis Haskellers put on them. Oftentimes projects will have a Types module; if I find one, this is where I try to start when learning an unfamiliar library.
Note that often the most important part of the generated documentation will not be the types or the functions defined, but the typeclass instances that each type defines. By extending existing typeclasses, whatever types the library creates become easily plug-in-able to lots of existing code and other libraries, but on the Haddock side it means that the functionality that you'll use all the time can be hard to discover, buried as what looks like a footnote to the rest of the library.
Now, reading the generated documentation is useful, but I also try to play around with a library as quickly as possible to get a feel for it. Usually I'll boot up an REPL with the library loaded using stack repl --package <package-name>. That way I can immediately try out functions and see what they do.
Let's take a look at understanding a specific example: the uuid package, for working with... UUIDs. If you don't know what a UUID is (also sometimes called a GUID), it's basically just a random 128-bit number used when you need to give something a unique, referenceable identifier.
Popping open the top-level module, we see our main player: the UUID type. Presumably this is what we'll be passing around and working with. So let's try to get one into our REPL.
How do we generate one? Perusing the docs, we'd expect to see some function of type IO UUID, since we know that we need randomness to create one. Lo and behold, we find said function in Data.UUID.V4: nextRandom. Let's give it a shot:
λ> import Data.UUID.V4
λ> nextRandom
da93c30a-7d36-4fc9-bffc-6788c1842b82Splendid!
Let's say uuid didn't provide this convenience function. Or perhaps we want to be able to control the seed used to generate UUIDs. We could actually still use the library to do what we want, but pulling it off isn't as easy or obvious as predefined library functions. The functions we want don't exist; where do we look now? Next on the list: look at the typeclass instances.
Scanning through the list of instances for UUID, we see a lot of the usual suspects. But one instance catches the eye: an instance for Random. Knowing that Random allows us to generate instances of this type using an RNG, the pieces fall into place: we could import the random package and use it to give us a generator, or to always use a certain seed for the PRNG. In other words, despite looking fairly innocuous on the page, this instance for Random is actually our primary interface for creating UUIDs.
Let's take a look at understanding another library: the time library for handling and manipulating timestamps, dates, time zones, etc. Popping open the topmost module, the library author has made our lives a little easier: there's a listing of all the most important types and when to use them. In this case, let's say I'm trying to get the closest Sunday before the current date. I find it's usually easier to understand a library when I go in with a specific goal in mind. Looking at the types that time provides, that means I'm trying to produce a function with type IO Day.

We know that we'll need a function to get the current date, so let's start from there. Does the library itself provide an IO Day somewhere? Clicking into the documentation for the Day type doesn't bring up anything that looks useful, so that's a bust. The index of types seems to be in descending order of importance, so let's take a look at UTCTime.
We finally find something interesting: getCurrentTime :: IO UTCTime. Does this do what we think it does?
λ> import Data.Time
λ> getCurrentTime
2019-05-27 22:18:04.980651 UTCNice!
Now we need a way to convert this into a Day. Looking through the modules for both UTCTime and Day, we don't see any top-level functions that take in a UTCTime and return a Day. But the function we're looking for is actually right under our noses, on the definition of the UTCTime type:
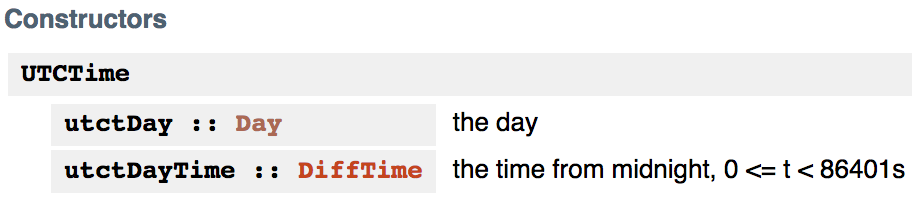
Just like with typeclass instances, the automatic accessor functions defined by record types can be some of the most important things a library exports, but they tend to look rather innocuous on the page. In this case, the function we were looking for is called utctDay.
λ> import Data.Time
λ> utctDay <$> getCurrentTime
2019-05-27At this point, to get to our desired previous-Sunday-function, all we need is some way to construct a new Day based on this date, but with the day of the week modified. In other words, we'd want to specifically look for functions with signatures of the form Day -> ... and ... -> Day.
Exercise: Implement the rest of the 'previous closest Sunday' function by browsing through the time library, using what you've learned.
Once I've gotten to the point where I'm up and running with a library, one common thing I want to do is to look at a specific function or type's definition.
The easiest way to do this is to use GHCi's built-in :info command to locate things:
λ> import Control.Lens
λ> :info (^?)
(^?) :: s -> Getting (Data.Monoid.First a) s a -> Maybe a
-- Defined in ‘Control.Lens.Fold’
infixl 8 ^?And if we go look in the documentation for the Control.Lens.Fold module, lo and behold:

Another common query I have is: is there a function in this library with this specific type signature? Especially with very abstract types, you'll often know exactly what the signature is of the function you want, but not what it's named or what module it's defined in. Thankfully, this is exactly where Hoogle shines; it even lets you narrow down by specific package.
While there are ways to get Hoogle set up locally and use the versions of packages in project, I've never had much success with getting them working; personally I just use the web Hoogle interface.
As a digression, both the function/type locator and signature search are things that I feel should be included in Hackage's web interface. But such is life.
Be careful when browsing Haddock documentation directly from Hackage; the version of the library you're using will often not be the latest on Hackage! I've had lots of frustrating experiences where functions that are in the documentation just seem to not exist, until I realise that I'm using an older version of the package that doesn't have those features yet. You can always open documentation that's current with your project using Stack itself:
$ stack haddock --open <dependency-name>You can even do this for your own project to see what documentation would look like for end-users of your code.
Finally, remember that you can always jump directly to the source code from the Haddock documentation. The code is even nicely hyperlinked by the functions/types used! I find that Haskell libraries are often surprisingly easy to read, especially since the language feels like it forces you to break things up into smaller chunks. If you ever find yourself trying to figure out how some function is doing some transformation (e.g. this HTTP library must be converting the username and password I'm giving it to an Authorization header somewhere), don't be afraid to just pop open the source code and poke around.
The answer of how to read Haskell documentation could be summed up as: follow the types. And unfortunately, you'll probably also have to read a lot of Haddock-generated documentation to get a feel for how best to do that. I hope that with this, you'll find yourself more comfortable diving into poorly-documented Haskell libraries. I bemoan the fact that such libraries exist, but begrudgingly admit that for the forseeable future, if you want to get anything done in Haskell, you'll need to be willing to excavate their docs.
Found this helpful? Got a particularly hairy library you're trying to dive into? Talk to me!
Before you close that tab...
Want to write practical, production-ready Haskell? Tired of broken libraries, barebones documentation, and endless type-theory papers only a postdoc could understand? I want to help. Subscribe below and you'll get useful techniques for writing real, useful programs straight in your inbox.
Absolutely no spam, ever. I respect your email privacy. Unsubscribe anytime.